



To SRE and Back Again… A DevOps Tale
- octubre 20, 2020
Site Reliability Engineering (SRE) has been around for some time now, yet it’s remained amorphous to many – even those of us in the business. Made famous by Google, the company defines SRE as, “what you get when you treat operations as if it’s a software problem.” Yet, this doesn’t fully address the depth of the term or what it represents. As SRE continues to gain momentum, let’s take a deeper look at what it is, how it relates to DevOps, and where to start.
What is SRE?
A code-centric approach, SRE creates scalability by enabling teams to write once and apply the solution multiple times. Add in the automation of repetitive, manual tasks and you can see where the reliability in Site Reliability Engineering enters the scene. More strategically, though, are the data-driven decisions that automation empowers. With critical data points in hand, SRE empowers teams to focus and implement solutions that are focused on delivering ideal outcomes for customers.
Reduce Organizational Silos
SRE allows cross-functional teams to flourish as operations team members who can write code share the same skills with product development team members. And, when everyone on a team has the same or similar skill set, the team can do almost anything given that everyone can ramp up and contribute to a project.
Data-Based Decision Making
SRE has a strong measurement focus, gathering evidence and data for continuous improvement. With decisions based on data related to service health, bugs, system efficiency and more, SRE teams can provide macro- and micro-level feedback on areas for improvement across the development and operations pipeline. SRE data unlocks previously hidden insights into what problems impact customers the most and helps teams prioritize their resolution.
Focus on Automation
SREs rely on automation to reduce manual work, primarily of monitoring and running services in production. Google’s book on SRE sums it well saying, “Eliminating toil is one of SRE’s most important tasks and is the subject of Eliminating Toil. We define toil as mundane, repetitive operational work providing no enduring value, which scales linearly with service growth.” Automation extends as well to traditional DevOps principles as well, like managing a herd of replaceable servers (cattle), rather than unique, irreplaceable servers (pets) and building self-healing software systems.
DevOps vs SRE
If these descriptions sound a little like DevOps, you aren’t wrong. As you can see in this Venn diagram, SRE shares commonalities with DevOps, Development and Operations.
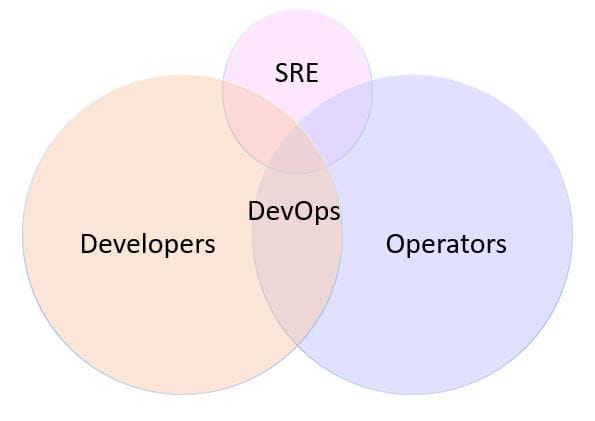
Yet, to help solidify the difference between DevOps and SRE, it can be helpful to think of SRE as impacting Operations just as DevOps impacted Development. SRE is an evolution for Operations in which it increases velocity as teams apply code and automation to operational activities. While DevOps provides continuous deployment, and DevOps teams may implement alerting and/or monitoring systems, at the end of the day, their mandate is not to manage and maintain the system. On the other hand, SRE has a clear focus on taking responsibility for operational execution, writing code, automating, testing, and running products in production.
Where to Start
So, all of this sounds great and you want to take the first steps to implement SRE. Where do you even begin? I recommend starting with a team and a service or application and get on the same page regarding your service level commitments. Once you’ve agreed on these, you can create an error budget policy and once you do all that you’re ready to do some monitoring and alerting. Let’s take each of these in detail:
Define Down
What does “down” really mean for your application? This is a key question for the team and its customer to answer. For example, if a service within the application is down, does that mean that the entire app is down? Or can it be replaced with something generic until it’s available again? These are the types of questions the team should work to answer to define “down” for a given app or service. As you discuss with your team and other stakeholders, consider the pillars behind reliability, such as:
- Availability – At the most basic level, is the app or service functioning and operational?
- Latency – How long does a user have to wait for a response from the service?
- Throughput – How many users can the service handle simultaneously and how does that affect the service queue?
- Correctness – Does the application provide accurate results or outputs?
- Quality – Is the service overloaded and need to downgrade its quality to perform?
- Freshness – How fresh or stale is the data being served by the application?
- Durability – Does the application perform consistently over time without failure?
While these are a few common examples, your app or service may have its own characteristics that will impact the definition of down.
Determine SLIs, SLOs and SLAs
Once you have a definition of down, teams should move on to defining their Service Level Indicators (SLIs), Service Level Objectives (SLOs) and Service Level Agreements (SLAs). Often cascading from one another, SLIs typically inform SLOs which, in turn, inform SLAs. As you can see in the graph below, the SLI should be an exact service-related metric.

Once SLIs are determined, SLOs can be decided. The SLO should always be a percentage of 100, with 100 being defined as everything up and working, and 0 defined as nothing up or working. The SLO is the minimum acceptable percentage out of 100 that the team agrees to meet or exceed for the application – defined by the definition of down and corresponding SLIs.
If the application or service is customer-facing, a business owner should take the SLO and turn it into an SLA for the customer. Note that SLOs should be stricter than SLAs because even if something detrimental happens, you can still meet your customer expectation; having a buffer between the two helps ensure customer satisfaction.
There are two important notes when looking at SLIs and SLOs. First, teams must define the timeframe associated with each – are you committing to 5 minutes, 5 days, or 5 months? While it depends on the application, we commonly see teams use a 30–day rolling window. Second, you should note as you develop your SLIs and SLOs that percentages can hide things. For example, 99% of 100 is much different than 99% of 1 million.
Error Budget Policy
Determining your SLO is critical to the next phase, the error budget. The error budget is what’s left after you consider your SLO. As an equation, think of it as 100% – SLO%. So, if your SLO is 96%, for example, your error budget is 4% (100-96). With the error budget determined, you can figure out how many errors you can afford to have. For example, if latency is your SLI, you can do the math to figure out how many requests can afford to have with a latency below your 200ms threshold. Using this data, you can then build dashboards and alarms.
In addition to the error budget, you will need to determine an error budget policy – both for missing or exceeding the budget. For example, if you come in under budget, you might consider increasing release velocity or tightening the SLO. Conversely, if you are over budget, you might set a policy to decrease release velocity or relax the SLO.
Alerting
Alerting helps SRE teams measure and track SLIs and SLO progress. While the alerts you set will depend heavily on the tooling you have and the SLIs you’re tracking, there are four broad considerations you should be thinking about as you establish alerts:
- Precision – The proportion of events detected that were significant. Precision is 100% if every alert corresponds to a significant event, not a false positive.
- Recall – The proportion of significant events detected. Recall is 100% if every significant event results in an alert.
- Detection Time – The length of time before the alert arrives. Note that long detection times can negatively impact your error budget.
- Reset Time – The length of time an alert continues to fire after an issue is resolved. Not that long reset times can result in alerts being ignored.
While there are many ways to set alerts, a good way to start is to set a generic alarm. In the example here, we set an alarm to alert us if the error rate is greater than or equal to 0.1% over a 10–minute period, for an SLO of 99.9% over 30 days.
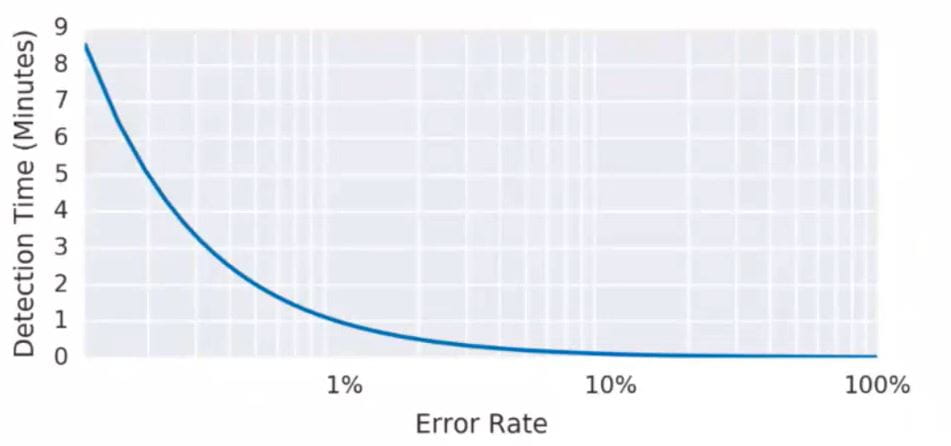
For each alarm, you’ll need to weigh the pros and cons. In this case, the generic alarm offers good recall and detection time while its precision is low.
Teams have found that they move from writing many noisy alarms that get ignored to creating alerts that have a direct connection to business objectives.
While SRE can work elegantly alongside DevOps, the discipline adds SLIs and SLOs as powerful ingredients to meaningfully impact operational excellence. SRE gives operations their moment to shine. We expect them to embrace the moment and build on it, growing the burgeoning momentum in the industry for SRE.
Subscribe to our blog